
Разпределение. Разпределение на Пиърсън Плътност на вероятността ... Уикипедия
разпределение хи-квадрат- разпределение хи квадрат - Теми защита на информация EN разпределение хи квадрат ... Ръководство за технически преводач
разпределение хи-квадрат- Вероятностно разпределение на непрекъсната случайна променлива със стойности от 0 до, чиято плътност се дава по формулата, където 0 за параметър =1,2,...; – гама функция. Примери. 1) Сума от квадрати на независими нормализирани произволни произволни... ... Речник на социологическата статистика
РАЗПРЕДЕЛЕНИЕ ХИ-КВАДРАТ (хи2)- Разпределение на случайна променлива chi2., ако се вземат произволни извадки с размер 1 от нормална дистрибуциясъс средна (и дисперсия q2, тогава chi2 = (X1 u)2/q2, където X е избраната стойност. Ако размерът на извадката се увеличи произволно до N, тогава chi2 =... ...
Плътност на вероятността ... Уикипедия
- (Разпределение Snedecor) Плътност на вероятността ... Wikipedia
Разпределение на Фишер Плътност на вероятността Функция на разпределение Параметри на число с ... Wikipedia
Една от основните концепции на теорията на вероятностите и математическата статистика. При модерен подходкато математически модел на изследваното случайно явление, се взема съответното вероятностно пространство (W, S, P), където W е набор от елементарни... Математическа енциклопедия
Гама разпределение Плътност на вероятността Функция на разпределение Параметри ... Wikipedia
РАЗПРОСТРАНЕНИЕ F- Теоретично вероятностно разпределение на случайна променлива F. Ако произволни извадки с размер N се изтеглят независимо от нормална популация, всяка генерира разпределение хи-квадрат със степен на свобода = N. Съотношението на две такива... ... Речникв психологията
Книги
- Теория на вероятностите и математическа статистика в задачите. Повече от 360 задачи и упражнения, Borzykh D.A.. Предлаганото ръководство съдържа задачи с различни нива на сложност. Основният акцент обаче е върху задачите със средна сложност. Това се прави умишлено, за да се насърчат учениците да...
Помислете за разпределението Хи-квадрат. Използване на функция MS EXCELCH2.DIST() Нека начертаем функцията на разпределение и плътността на вероятността и да обясним използването на това разпределение за целите на математическата статистика.
Хи-квадрат разпределение (X 2, XI2,АнглийскиЧи- на квадратразпространение) използвани в различни методи на математическата статистика:
- по време на строителството;
- в ;
- при (емпиричните данни съгласуват ли се с нашето предположение за теоретичната функция на разпределение или не, англ. Goodness-of-fit)
- at (използва се за определяне на връзката между две категорични променливи, английски Хи-квадрат тест на асоцииране).
Определение: Ако x 1 , x 2 , …, x n са независими случайни променливи, разпределени върху N(0;1), тогава разпределението на случайната променлива Y=x 1 2 + x 2 2 +…+ x n 2 има разпространение X 2 с n степени на свобода.
Разпределение X 2 зависи от един наречен параметър степен на свобода (df, степенинасвобода). Например при изграждане брой степени на свободае равно на df=n-1, където n е размерът проби.
Плътност на разпространение X 2
изразено с формулата:
Функционални графики
Разпределение X 2 има асиметрична форма, равна на n, равна на 2n.
IN примерен файл на листа Графикададено графики на плътността на разпределениетовероятности и кумулативна функция на разпределение.
Полезен имот CH2 разпределения
Нека x 1 , x 2 , …, x n са независими случайни променливи, разпределени в нормален закон
със същите параметри μ и σ, и X сре средноаритметичнотези x стойности.
Тогава произволна стойност гравен
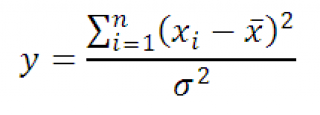
То има X 2 -разпределениес n-1 степени на свобода. Използвайки дефиницията, горният израз може да бъде пренаписан, както следва:

следователно разпределение на пробитестатистика y, at пробаот нормална дистрибуция, То има X 2 -разпределениес n-1 степени на свобода.
Ще имаме нужда от този имот, когато. защото дисперсияможе би просто положително число, А X 2 -разпределениетогава се използва за оценката му гд.б. >0, както е посочено в дефиницията.
CH2 разпределение в MS EXCEL
В MS EXCEL, като се започне от версия 2010, за X 2 -разпределенияима специална функция CHI2.DIST(), английско име– CHISQ.DIST(), който ви позволява да изчислявате плътност на вероятността(вижте формулата по-горе) и (вероятността една случайна променлива X да има CI2-разпространение, ще приеме стойност, по-малка или равна на x, P(X<= x}).
Забележка: Защото CH2 разпределениее частен случай, тогава формулата =GAMMA.DIST(x;n/2;2;TRUE)за положително цяло число n връща същия резултат като формулата =CHI2.DIST(x;n; TRUE)или =1-CHI2.DIST.PH(x;n) . И формулата =GAMMA.DIST(x;n/2;2;FALSE)връща същия резултат като формулата =CHI2.DIST(x;n; FALSE), т.е. плътност на вероятността CH2 разпределения.
Функцията HI2.DIST.PH() връща разпределителна функция, по-точно дясностранна вероятност, т.е. P(X > x). Очевидно е, че равенството е вярно
=CHI2.DIST.PH(x;n)+CHI2.DIST(x;n;TRUE)=1
защото първият член изчислява вероятността P(X > x), а вторият P(X<= x}.
Преди MS EXCEL 2010, EXCEL имаше само функцията CHIDIST(), която ви позволява да изчислите дясната вероятност, т.е. P(X > x). Възможностите на новите функции на MS EXCEL 2010 XI2.DIST() и XI2.DIST.PH() покриват възможностите на тази функция. Функцията CH2DIST() е оставена в MS EXCEL 2010 за съвместимост.
CHI2.DIST() е единствената функция, която връща плътност на вероятността на разпределението chi2(третият аргумент трябва да е FALSE). Останалите функции се връщат кумулативна функция на разпределение, т.е. вероятност случайната променлива да приеме стойност от посочения диапазон: P(X<= x}.
Горните функции на MS EXCEL са дадени в .
Примери
Нека намерим вероятността случайната променлива X да приеме стойност, по-малка или равна на дадената х: P(X<= x}. Это можно сделать несколькими функциями:
CHI2.DIST(x; n; TRUE)
=1-HI2.DIST.PH(x; n)
=1-CHI2DIST(x; n)
Функцията CH2.DIST.PH() връща вероятността P(X > x), така наречената дясна вероятност, така че да се намери P(X<= x}, необходимо вычесть ее результат от 1.
Нека намерим вероятността случайната променлива X да приеме стойност, по-голяма от дадена х: P(X > x). Това може да стане с няколко функции:
1-CHI2.DIST(x; n; TRUE)
=HI2.DIST.PH(x; n)
=CHI2DIST(x; n)
Обратна функция на разпределение chi2
За изчисляване се използва обратната функция алфа- , т.е. за изчисляване на стойности хза дадена вероятност алфа, и хтрябва да отговаря на израза P(X<= x}=алфа.
Функцията CH2.INV() се използва за изчисляване доверителни интервали на дисперсията на нормалното разпределение.
Функцията CHI2.OBR.PH() се използва за изчисляване, т.е. ако ниво на значимост е указано като аргумент на функцията, например 0,05, тогава функцията ще върне стойност на случайната променлива x, за която P(X>x)=0,05. За сравнение: функцията XI2.INR() ще върне стойност на случайната променлива x, за която P(X<=x}=0,05.
В MS EXCEL 2007 и по-рано, вместо HI2.OBR.PH(), се използва функцията HI2OBR().
Горните функции могат да се сменят, т.к следните формули връщат същия резултат:
=CHI.OBR(алфа;n)
=HI2.OBR.PH(1-алфа;n)
=CHI2INV(1- алфа;n)
Някои примери за изчисления са дадени в примерен файл в листа с функции.
MS EXCEL функционира, използвайки CH2 разпределението
По-долу е съответствието между руски и английски имена на функции:
CH2.DIST.PH() - английски. име CHISQ.DIST.RT, т.е. ХИ-квадратно РАЗПРЕДЕЛЕНИЕ Дясна опашка, дясноразпределение Хи-квадрат(d)
CH2.OBR() - английски. име CHISQ.INV, т.е. CHI-квадратно разпределение INVerse
CH2.PH.OBR() - английски. име CHISQ.INV.RT, т.е. CHI-квадратно разпределение INVerse Right Tail
CH2DIST() - английски. име CHIDIST, функция, еквивалентна на CHISQ.DIST.RT
CH2OBR() - английски. име CHIINV, т.е. CHI-квадратно разпределение INVerse
Оценка на параметрите на разпределението
защото обикновено CH2 разпределениеизползвани за целите на математическата статистика (изчисление доверителни интервали, тестване на хипотези и др.),и почти никога за конструиране на модели на реални стойности, тогава за това разпределение обсъждането на оценката на параметрите на разпределението не се провежда тук.
Апроксимация на разпределението на CI2 чрез нормалното разпределение
С броя на степените на свобода n>30 разпределение X 2добре приблизително нормална дистрибуцияс средна стойностμ=n и дисперсия σ=2*n (вижте примерен листов файл Приближение).
Хи-квадрат разпределение
С помощта на нормалното разпределение се дефинират три разпределения, които сега често се използват в статистическата обработка на данни. Това са разпределенията на Пиърсън („хи-квадрат“), Студент и Фишер.
Ще се съсредоточим върху разпределението („хи-квадрат“). Това разпределение е изследвано за първи път от астронома Ф. Хелмерт през 1876 г. Във връзка с теорията на грешките на Гаус той изучава сумите от квадратите на n независими стандартно нормално разпределени случайни променливи. По-късно Карл Пиърсън дава името "хи-квадрат" на тази функция на разпределение. И сега разпределението носи неговото име.
Поради тясната си връзка с нормалното разпределение, разпределението h2 играе важна роля в теорията на вероятностите и математическата статистика. Разпределението h2 и много други разпределения, които се определят от разпределението h2 (например разпределението на Стюдънт), описват примерни разпределения на различни функции от нормално разпределени резултати от наблюдение и се използват за конструиране на доверителни интервали и статистически тестове.
Разпределение на Пиърсън (хи - квадрат) - разпределение на случайна променлива, където X1, X2,..., Xn са нормални независими случайни променливи, като математическото очакване на всяка от тях е нула, а стандартното отклонение е единица.
Сбор на квадрати
разпределени според закона (“хи - квадрат”).
В този случай броят на термините, т.е. n се нарича "брой степени на свобода" на разпределението хи-квадрат. С увеличаването на броя на степените на свобода разпределението бавно се доближава до нормалното.
Плътността на това разпределение

И така, разпределението h2 зависи от един параметър n - броя на степените на свобода.
Функцията на разпределение h2 има формата:
ако h2?0. (2.7.)
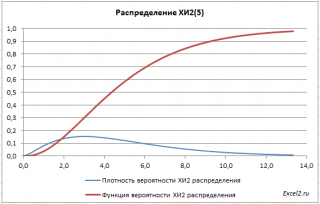
Фигура 1 показва графика на функциите на плътността на вероятността и разпределението h2 за различни степени на свобода.
Фигура 1 Зависимост на плътността на вероятността q (x) в разпределението h2 (chi - квадрат) за различен брой степени на свобода.

Моменти на разпределението хи-квадрат:
Разпределението хи-квадрат се използва при оценяване на дисперсията (използване на доверителен интервал), тестване на хипотези за съгласие, хомогенност, независимост, предимно за качествени (категоризирани) променливи, които приемат краен брой стойности, както и в много други задачи на анализ на статистически данни .
"Хи-квадрат" в проблемите на статистическия анализ на данни
Статистическите методи за анализ на данни се използват в почти всички области на човешката дейност. Те се използват винаги, когато е необходимо да се получат и обосноват някакви преценки за група (обекти или субекти) с някаква вътрешна хетерогенност.
Съвременният етап на развитие на статистическите методи може да се брои от 1900 г., когато англичанинът К. Пиърсън основава списанието "Биометрика". Първата третина на ХХ век. премина под знака на параметричната статистика. Методите са изследвани въз основа на анализ на данни от параметрични семейства от разпределения, описани от криви на семейство Пиърсън. Най-популярно беше нормалното разпределение. За проверка на хипотезите са използвани тестовете на Pearson, Student и Fisher. Предложени са методът на максималната вероятност и дисперсионният анализ и са формулирани основните идеи за планиране на експеримента.
Разпределението хи-квадрат е едно от най-широко използваните в статистиката за тестване на статистически хипотези. Въз основа на разпределението хи-квадрат е конструиран един от най-мощните тестове за добро съответствие - хи-квадрат тестът на Пиърсън.
Критерият за съгласие е критерият за проверка на хипотезата за приетия закон на неизвестно разпределение.
Тестът h2 ("хи-квадрат") се използва за проверка на хипотезата за различни разпределения. Това е неговото достойнство.
Формулата за изчисление на критерия е равна на

където m и m" са съответно емпирични и теоретични честоти
въпросното разпределение;
n е броят на степените на свобода.
За да проверим, трябва да сравним емпиричните (наблюдавани) и теоретичните (изчислени при предположението за нормално разпределение) честоти.
Ако емпиричните честоти напълно съвпадат с изчислените или очаквани честоти, S (E - T) = 0 и критерият h2 също ще бъде равен на нула. Ако S (E - T) не е равно на нула, това ще означава несъответствие между изчислените честоти и емпиричните честоти на серията. В такива случаи е необходимо да се оцени значимостта на критерия h2, който теоретично може да варира от нула до безкрайност. Това се прави чрез сравняване на действителната стойност на h2f с нейната критична стойност (h2st).Нулевата хипотеза, т.е. предположението, че несъответствието между емпиричните и теоретичните или очакваните честоти е случайно, се опровергава, ако h2f е по-голямо или равно на h2st за приетото ниво на значимост (a) и броя на степените на свобода (n).
Разпределението на вероятните стойности на случайната променлива h2 е непрекъснато и асиметрично. Зависи от броя на степените на свобода (n) и се доближава до нормално разпределение с увеличаване на броя на наблюденията. Следователно прилагането на критерия h2 за оценка на дискретни разпределения е свързано с някои грешки, които влияят на неговата стойност, особено при малки извадки. За да се получат по-точни оценки, извадката, разпределена в серията вариации, трябва да има поне 50 опции. Правилното прилагане на критерия h2 също изисква честотите на вариантите в екстремните класове да не са по-малки от 5; ако има по-малко от 5 от тях, тогава те се комбинират с честотите на съседни класове, така че общата сума да е по-голяма или равна на 5. Според комбинацията от честоти броят на класовете (N) намалява. Броят на степените на свобода се определя от вторичния брой класове, като се вземе предвид броят на ограниченията на свободата на вариация.
Тъй като точността на определяне на критерия h2 до голяма степен зависи от точността на изчисляване на теоретичните честоти (T), трябва да се използват незакръглени теоретични честоти, за да се получи разликата между емпиричните и изчислените честоти.
Като пример, нека вземем проучване, публикувано на уебсайт, посветен на приложението на статистически методи в хуманитарните науки.
Хи-квадрат тестът ви позволява да сравнявате честотните разпределения, независимо дали те са нормално разпределени или не.
Честотата се отнася до броя на случванията на дадено събитие. Обикновено честотата на възникване на събитията се разглежда, когато променливите се измерват по скала от имена и другите им характеристики, освен честотата, са невъзможни или проблематични за избор. С други думи, когато една променлива има качествени характеристики. Освен това много изследователи са склонни да преобразуват резултатите от тестовете в нива (високо, средно, ниско) и да съставят таблици с разпределение на резултатите, за да открият броя на хората на тези нива. За да се докаже, че в едно от нивата (в една от категориите) броят на хората наистина е по-голям (по-малък) също се използва коефициентът Хи-квадрат.
Нека разгледаме най-простия пример.
Беше проведен тест сред по-младите юноши за идентифициране на самочувствието. Резултатите от теста бяха преобразувани в три нива: високо, средно, ниско. Честотите бяха разпределени както следва:
Висока (B) 27 души.
Средно (C) 12 души.
Ниска (L) 11 души
Очевидно е, че по-голямата част от децата имат високо самочувствие, но това трябва да бъде доказано статистически. За целта използваме теста Хи-квадрат.
Нашата задача е да проверим дали получените емпирични данни се различават от теоретично еднакво вероятните. За да направите това, трябва да намерите теоретичните честоти. В нашия случай теоретичните честоти са еднакво вероятни честоти, които се намират чрез добавяне на всички честоти и разделяне на броя на категориите.
В нашия случай:
(B + C + H)/3 = (27+12+11)/3 = 16,6
Формула за изчисляване на хи-квадрат теста:
h2 = ?(E - T)? / T
Изграждаме масата:
|
Емпиричен (E) |
Теоретичен (T) |
||
Намерете сумата от последната колона:
Сега трябва да намерите критичната стойност на критерия, като използвате таблицата с критични стойности (Таблица 1 в Приложението). За да направим това, се нуждаем от броя на степените на свобода (n).
n = (R - 1) * (C - 1)
където R е броят на редовете в таблицата, C е броят на колоните.
В нашия случай има само една колона (което означава оригиналните емпирични честоти) и три реда (категории), така че формулата се променя - изключваме колоните.
n = (R - 1) = 3-1 = 2
За вероятността за грешка p?0,05 и n = 2, критичната стойност е h2 = 5,99.
Получената емпирична стойност е по-голяма от критичната – разликите в честотите са значими (h2 = 9.64; p? 0.05).
Както можете да видите, изчисляването на критерия е много просто и не отнема много време. Практическата стойност на хи-квадрат теста е огромна. Този метод е най-ценен, когато се анализират отговорите на въпросниците.
Нека да разгледаме по-сложен пример.
Например, един психолог иска да знае дали е вярно, че учителите са по-предубедени към момчетата, отколкото към момичетата. Тези. по-вероятно е да хвали момичета. За да направи това, психологът анализира характеристиките на учениците, написани от учителите, за честотата на срещане на три думи: „активен“, „усърден“, „дисциплиниран“ и също бяха преброени синонимите на думите. Данните за честотата на срещане на думите бяха въведени в таблицата:
За обработка на получените данни използваме теста хи-квадрат.
За да направим това, ще изградим таблица на разпределението на емпиричните честоти, т.е. тези честоти, които наблюдаваме:
Теоретично очакваме, че честотите ще бъдат равномерно разпределени, т.е. честотата ще бъде разпределена пропорционално между момчета и момичета. Нека изградим таблица с теоретични честоти. За да направите това, умножете сумата на реда по сумата на колоната и разделете полученото число на общата сума (s).
Финалната таблица за изчисления ще изглежда така:
h2 = ?(E - T)? / T
n = (R - 1), където R е броят на редовете в таблицата.
В нашия случай хи-квадрат = 4,21; n = 2.
Използвайки таблицата с критични стойности на критерия, намираме: с n = 2 и ниво на грешка от 0,05, критичната стойност h2 = 5,99.
Получената стойност е по-малка от критичната стойност, което означава, че нулевата хипотеза е приета.
Извод: учителите не отдават значение на пола на детето, когато пишат характеристики за него.
Приложение
Критични точки на разпространение h2
Министерство на образованието и науката на Руската федерация
Федерална агенция за образование на град Иркутск
Байкалски държавен университет по икономика и право
Катедра "Информатика и кибернетика".
Хи-квадрат разпределение и неговите приложения
Колмикова Анна Андреевна
Студент 2-ра година
група ИС-09-1
Иркутск 2010 г
Въведение
1. Хи-квадрат разпределение
Приложение
Заключение
Библиография
Въведение
Как се използват подходите, идеите и резултатите от теорията на вероятностите в нашия живот?
Основата е вероятностен модел на реално явление или процес, т.е. математически модел, в който обективните връзки са изразени от гледна точка на теорията на вероятностите. Вероятностите се използват предимно за описание на несигурностите, които трябва да се вземат предвид при вземането на решения. Това се отнася както за нежелани възможности (рискове), така и за привлекателни („щастлив шанс”). Понякога произволността се въвежда умишлено в ситуация, например при теглене на жребий, произволен избор на единици за контрол, провеждане на лотарии или провеждане на потребителски проучвания.
Теорията на вероятностите позволява една вероятност да се използва за изчисляване на други, които представляват интерес за изследователя.
Вероятностният модел на явление или процес е в основата на математическата статистика. Използват се две паралелни серии от понятия – тези, свързани с теорията (вероятностен модел) и тези, свързани с практиката (извадка от резултатите от наблюдение). Например, теоретичната вероятност съответства на честотата, намерена от извадката. Математическото очакване (теоретична серия) съответства на средноаритметичното извадково (практическа серия). По правило характеристиките на извадката са оценки на теоретичните. В същото време количествата, свързани с теоретичните серии, „са в главите на изследователите“, се отнасят до света на идеите (според древногръцкия философ Платон) и не са достъпни за директно измерване. Изследователите разполагат само с примерни данни, с които се опитват да установят свойствата на теоретичен вероятностен модел, който ги интересува.
Защо се нуждаем от вероятностен модел? Факт е, че само с негова помощ свойствата, установени от анализа на конкретна проба, могат да бъдат пренесени върху други проби, както и върху цялата така наречена генерална съвкупност. Терминът "популация" се използва, когато се говори за голяма, но ограничена колекция от изследвани единици. Например за съвкупността от всички жители на Русия или за съвкупността от всички потребители на разтворимо кафе в Москва. Целта на маркетинговите или социологическите проучвания е да прехвърлят твърдения, получени от извадка от стотици или хиляди хора, към популации от няколко милиона души. При контрола на качеството партида от продукти действа като обща съвкупност.
За да се прехвърлят заключения от извадка към по-голяма популация, са необходими някои допускания относно връзката на характеристиките на извадката с характеристиките на тази по-голяма популация. Тези предположения се основават на подходящ вероятностен модел.
Разбира се, възможно е да се обработват примерни данни, без да се използва един или друг вероятностен модел. Например, можете да изчислите примерно средно аритметично, да преброите честотата на изпълнение на определени условия и т.н. Резултатите от изчислението обаче ще се отнасят само до конкретна извадка; прехвърлянето на заключенията, получени с тяхна помощ, към друга популация е неправилно. Тази дейност понякога се нарича „анализ на данни“. В сравнение с вероятностно-статистическите методи, анализът на данни има ограничена образователна стойност.
Така че използването на вероятностни модели, базирани на оценка и тестване на хипотези, използвайки характеристики на извадка, е същността на вероятностно-статистическите методи за вземане на решения.
Хи-квадрат разпределение
С помощта на нормалното разпределение се дефинират три разпределения, които сега често се използват в статистическата обработка на данни. Това са разпределенията на Pearson („хи-квадрат“), Student и Fisher.
Ще се съсредоточим върху разпространението
(„чи – квадрат“). Това разпределение е изследвано за първи път от астронома Ф. Хелмерт през 1876 г. Във връзка с теорията на грешките на Гаус той изучава сумите от квадратите на n независими стандартно нормално разпределени случайни променливи. Карл Пиърсън по-късно нарече тази функция на разпределение „хи-квадрат“. И сега разпределението носи неговото име.Поради тясната си връзка с нормалното разпределение, разпределението χ2 играе важна роля в теорията на вероятностите и математическата статистика. Разпределението χ2 и много други разпределения, които се определят от разпределението χ2 (например разпределението на Стюдънт), описват примерни разпределения на различни функции от нормално разпределени резултати от наблюдение и се използват за конструиране на доверителни интервали и статистически тестове.
Разпределение на Пиърсън
(chi - квадрат) – разпределение на случайна променлива, където X1, X2,..., Xn са нормални независими случайни променливи, като математическото очакване на всяка от тях е нула, а стандартното отклонение е единица.Сбор на квадрати
разпределени по закон
(„чи – квадрат“).В този случай броят на термините, т.е. n се нарича "брой степени на свобода" на разпределението хи-квадрат.С увеличаването на броя на степените на свобода разпределението бавно се доближава до нормалното.
Плътността на това разпределение
И така, разпределението на χ2 зависи от един параметър n – броя на степените на свобода.
Функцията на разпределение χ2 има формата:
ако χ2≥0. (2.7.)
Фигура 1 показва графика на плътността на вероятността и функцията на разпределение χ2 за различни степени на свобода.
Снимка 1Зависимост на плътността на вероятността φ (x) в разпределението χ2 (chi – квадрат) за различен брой степени на свобода.
Моменти на разпределението хи-квадрат:
Разпределението хи-квадрат се използва при оценяване на дисперсията (използване на доверителен интервал), тестване на хипотези за съгласие, хомогенност, независимост, предимно за качествени (категоризирани) променливи, които приемат краен брой стойности, както и в много други задачи на анализ на статистически данни .
2. "Хи-квадрат" в задачите на статистическия анализ на данни
Статистическите методи за анализ на данни се използват в почти всички области на човешката дейност. Те се използват винаги, когато е необходимо да се получат и обосноват някакви преценки за група (обекти или субекти) с някаква вътрешна хетерогенност.
Съвременният етап на развитие на статистическите методи може да се брои от 1900 г., когато англичанинът К. Пиърсън основава списанието "Биометрика". Първата третина на ХХ век. премина под знака на параметричната статистика. Методите са изследвани въз основа на анализ на данни от параметрични семейства от разпределения, описани от криви на семейство Пиърсън. Най-популярно беше нормалното разпределение. За проверка на хипотезите са използвани тестовете на Pearson, Student и Fisher. Предложени са методът на максималната вероятност и дисперсионният анализ и са формулирани основните идеи за планиране на експеримента.
Разпределението хи-квадрат е едно от най-широко използваните в статистиката за тестване на статистически хипотези. Въз основа на разпределението хи-квадрат е конструиран един от най-мощните тестове за добро съответствие - хи-квадрат тестът на Пиърсън.
Критерият за съгласие е критерият за проверка на хипотезата за приетия закон на неизвестно разпределение.
Тестът χ2 (хи-квадрат) се използва за проверка на хипотезата за различни разпределения. Това е неговото достойнство.
Формулата за изчисление на критерия е равна на
където m и m’ са съответно емпирични и теоретични честоти
въпросното разпределение;
n е броят на степените на свобода.
За да проверим, трябва да сравним емпиричните (наблюдавани) и теоретичните (изчислени при предположението за нормално разпределение) честоти.
Ако емпиричните честоти напълно съвпадат с изчислените или очаквани честоти, S (E – T) = 0 и критерият χ2 също ще бъде равен на нула. Ако S (E – T) не е равно на нула, това ще означава несъответствие между изчислените честоти и емпиричните честоти на серията. В такива случаи е необходимо да се оцени значимостта на критерия χ2, който теоретично може да варира от нула до безкрайност. Това се прави чрез сравняване на действително получената стойност на χ2ф с нейната критична стойност (χ2st).Нулевата хипотеза, т.е. предположението, че несъответствието между емпиричните и теоретичните или очакваните честоти е случайно, се опровергава, ако χ2ф е по-голямо или равно на χ2st за приетото ниво на значимост (a) и броя на степените на свобода (n).
Тестът \(\chi^2\) ("хи-квадрат", също "тест за съответствие на Пиърсън") има изключително широко приложение в статистиката. Най-общо можем да кажем, че се използва за тестване на нулевата хипотеза, че наблюдавана случайна променлива е обект на определен теоретичен закон за разпределение (за повече подробности вижте например). Конкретната формулировка на тестваната хипотеза ще варира в зависимост от случая.
В тази публикация ще опиша как работи критерият \(\chi^2\), като използвам (хипотетичен) пример от имунологията. Нека си представим, че сме провели експеримент, за да определим ефективността на потискане на развитието на микробно заболяване, когато в тялото се въведат подходящи антитела. В експеримента участваха общо 111 мишки, които разделихме на две групи, включващи съответно 57 и 54 животни. Първата група мишки получава инжекции от патогенни бактерии, последвани от въвеждане на кръвен серум, съдържащ антитела срещу тези бактерии. Животните от втората група послужиха за контрола - те получиха само бактериални инжекции. След известно време на инкубация се оказа, че 38 мишки са умрели, а 73 са оцелели. От загиналите 13 са от първа група, а 25 от втора (контролна). Нулевата хипотеза, тествана в този експеримент, може да бъде формулирана по следния начин: прилагането на серум с антитела няма ефект върху оцеляването на мишките. С други думи, ние твърдим, че наблюдаваните разлики в преживяемостта на мишките (77,2% в първата група срещу 53,7% във втората група) са напълно случайни и не са свързани с ефекта на антителата.
Получените в експеримента данни могат да бъдат представени под формата на таблица:
Обща сума |
|||
Бактерии + серум |
|||
Само бактерии |
|||
Обща сума |
Таблици като показаната се наричат таблици за непредвидени случаи. В разглеждания пример таблицата е с размери 2x2: има два класа обекти („Бактерии + серум“ и „Само бактерии“), които се изследват по два критерия („Мъртви“ и „Оцелели“). Това е най-простият случай на таблица за непредвидени обстоятелства: разбира се, както броят на изучаваните класове, така и броят на функциите може да бъде по-голям.
За да тестваме нулевата хипотеза, посочена по-горе, трябва да знаем каква би била ситуацията, ако антителата действително нямаха ефект върху оцеляването на мишките. С други думи, трябва да изчислите очаквани честотиза съответните клетки от таблицата за непредвидени обстоятелства. Как да го направим? В експеримента са загинали общо 38 мишки, което е 34,2% от общия брой на участващите животни. Ако прилагането на антитела не повлиява преживяемостта на мишките, трябва да се наблюдава еднакъв процент на смъртност и в двете експериментални групи, а именно 34,2%. Изчислявайки колко е 34,2% от 57 и 54, получаваме 19,5 и 18,5. Това са очакваните нива на смъртност в нашите експериментални групи. Очакваните проценти на оцеляване се изчисляват по подобен начин: тъй като са оцелели общо 73 мишки или 65,8% от общия брой, очакваните проценти на оцеляване ще бъдат 37,5 и 35,5. Нека създадем нова таблица за непредвидени обстоятелства, сега с очакваните честоти:
Мъртъв |
Оцелели |
Обща сума |
|
Бактерии + серум |
|||
Само бактерии |
|||
Обща сума |
Както виждаме, очакваните честоти са доста различни от наблюдаваните, т.е. прилагането на антитела изглежда има ефект върху оцеляването на мишки, заразени с патогена. Можем да определим количествено това впечатление с помощта на теста за съответствие на Pearson \(\chi^2\):
\[\chi^2 = \sum_()\frac((f_o - f_e)^2)(f_e),\]
където \(f_o\) и \(f_e\) са съответно наблюдаваните и очакваните честоти. Сумирането се извършва по всички клетки на таблицата. Така че за разглеждания пример имаме
\[\chi^2 = (13 – 19,5)^2/19,5 + (44 – 37,5)^2/37,5 + (25 – 18,5)^2/18,5 + (29 – 35,5)^2/35,5 = \]
Получената стойност на \(\chi^2\) достатъчно голяма ли е, за да отхвърли нулевата хипотеза? За да се отговори на този въпрос е необходимо да се намери съответната критична стойност на критерия. Броят на степените на свобода за \(\chi^2\) се изчислява като \(df = (R - 1)(C - 1)\), където \(R\) и \(C\) са числото на редове и колони в конюгацията на таблицата. В нашия случай \(df = (2 -1)(2 - 1) = 1\). Като знаем броя на степените на свобода, сега можем лесно да намерим критичната стойност \(\chi^2\), като използваме стандартната R функция qchisq() :
Така при една степен на свобода само в 5% от случаите стойността на критерия \(\chi^2\) надвишава 3,841. Стойността, която получихме, 6,79, значително надвишава тази критична стойност, което ни дава право да отхвърлим нулевата хипотеза, че няма връзка между прилагането на антитела и оцеляването на заразените мишки. Отхвърляйки тази хипотеза, рискуваме да сгрешим с вероятност по-малка от 5%.
Трябва да се отбележи, че горната формула за критерия \(\chi^2\) дава леко завишени стойности при работа с таблици за непредвидени обстоятелства с размер 2x2. Причината е, че разпределението на самия критерий \(\chi^2\) е непрекъснато, докато честотите на двоичните характеристики („умрял“ / „оцелял“) са по дефиниция дискретни. В тази връзка при изчисляване на критерия е прието да се въвежда т.нар корекция на непрекъснатостта, или Поправката на Йейтс :
\[\chi^2_Y = \sum_()\frac((|f_o - f_e| - 0,5)^2)(f_e).\]
Пиърсън "s Хи-квадрат тест с Йейтс"данни за корекция на непрекъснатостта: мишки X-квадрат = 5,7923, df = 1, p-стойност = 0,0161
Както виждаме, R автоматично прилага корекцията за непрекъснатост на Йейтс ( Хи-квадрат тест на Пиърсън с корекция за непрекъснатост на Йейтс). Стойността на \(\chi^2\), изчислена от програмата, беше 5,79213. Можем да отхвърлим нулевата хипотеза за липса на ефект на антитела с риск да сгрешим с вероятност от малко над 1% (p-стойност = 0,0161).


")
КУЛТУРА

Taos Rumble: Earth's Darkest Secret
 И нещо ще се раздвижи в нас")
„Стихотворението на Тютчев (Срещнах те - и всичко минало ...) И нещо ще се раздвижи в нас

Решение на диаграма на Вен онлайн

"скъпа" - малка къща с таван

Океани край бреговете на Евразия Морета край бреговете на Евразия

Какво е функция и нейните свойства Какво означава y x

Биография на разказа на Матвеева

Герой на Русия саксии Анатолий Петрович

Декабристкото въстание на 14 декември






